Search Knowledge
Search & Knowledge
Add RAG-style knowledge search to your agents using local vector indexes (.swsearch files) or PostgreSQL with pgvector. Build indexes with sw-search CLI and integrate using the native_vector_search skill.
Knowledge search transforms your agent from a general-purpose assistant into a domain expert. By connecting your agent to documents—FAQs, product manuals, policies, API docs—it can answer questions based on your actual content rather than general knowledge.
This is called RAG (Retrieval-Augmented Generation): when asked a question, the agent first retrieves relevant documents, then uses them to generate an accurate response. The result is more accurate, verifiable answers grounded in your authoritative sources.
When to Use Knowledge Search
Good use cases:
- Customer support with FAQ/knowledge base
- Product information lookup
- Policy and procedure questions
- API documentation assistant
- Internal knowledge management
- Training and onboarding assistants
Not ideal for:
- Real-time data (use APIs instead)
- Transactional operations (use SWAIG functions)
- Content that changes very frequently
- Highly personalized information (use database lookups)
Search System Overview
Build Time:
Runtime:
Backends:
Building Search Indexes
Use the sw-search CLI to create search indexes:
Chunking Strategies
Markdown Chunking (Recommended for Docs)
This strategy:
- Chunks at header boundaries
- Detects code blocks and extracts language
- Adds “code” tags to chunks containing code
- Preserves section hierarchy in metadata
Sentence Chunking
Installing Search Dependencies
Using Search in Agents
Add the native_vector_search skill to enable search:
Skill Configuration Options
pgvector Backend
For production deployments, use PostgreSQL with pgvector:
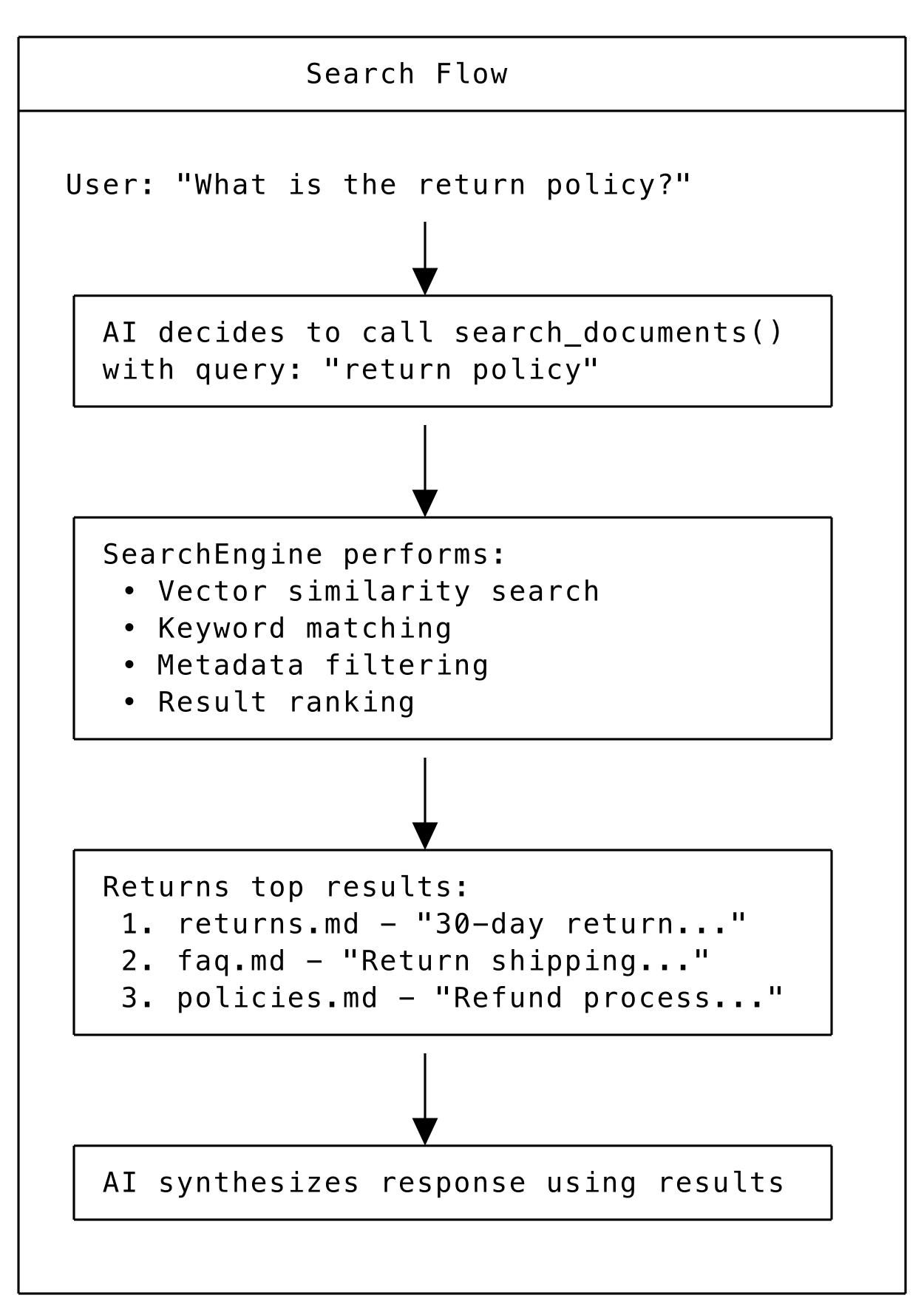
Search Flow
CLI Commands
Build Index
Validate Index
Search Index
Complete Example
This example uses a stub function for demonstration. In production, use the native_vector_search skill with a .swsearch index file built using sw-search.
Multiple Knowledge Bases
Add multiple search instances for different topics:
Understanding Embeddings
Search works by converting text into numerical vectors (embeddings) that capture semantic meaning. Similar concepts have similar vectors, enabling “meaning-based” search rather than just keyword matching.
How it works:
- At index time: Each document chunk is converted to a vector and stored
- At query time: The search query is converted to a vector
- Matching: Chunks with vectors closest to the query vector are returned
This means “return policy” will match documents about “refund process” or “merchandise exchange” even if they don’t contain those exact words.
Embedding quality matters:
- Better embeddings = better search results
- The SDK uses efficient embedding models optimized for search
- Different chunking strategies affect how well content is embedded
Index Management
When to Rebuild Indexes
Rebuild your search index when:
- Source documents are added, removed, or significantly changed
- You change chunking strategy
- You want to add or modify tags
- Search quality degrades
Rebuilding is fast for small document sets. For large collections, consider incremental updates.
Keeping Indexes Updated
For production systems, automate index rebuilding:
Index Size and Performance
Index size depends on:
- Number of documents
- Chunking strategy (more chunks = larger index)
- Embedding dimensions
Rough sizing:
- 100 documents (~50KB each) → ~10-20MB index
- 1,000 documents → ~100-200MB index
- 10,000+ documents → Consider pgvector for better performance
Query Optimization
Writing Good Prompts for Search
Help the AI use search effectively by being specific in your prompt:
Tuning Search Parameters
Adjust these parameters based on your content and use case:
count: Number of results to return
count=3: Focused answers, faster responsecount=5: Good balance (default)count=10: More comprehensive, but may include less relevant results
similarity_threshold: Minimum relevance score (0.0 to 1.0)
0.0: Return all results regardless of relevance0.3: Filter out clearly irrelevant results0.5+: Only high-confidence matches (may miss relevant content)
tags: Filter by document categories
Handling Poor Search Results
If search quality is low:
- Check chunking: Are chunks too large or too small?
- Review content: Is the source content well-written and searchable?
- Try different strategies: Markdown chunking for docs, sentence for prose
- Add metadata: Tags help filter irrelevant content
- Tune threshold: Too high filters good results, too low adds noise
Troubleshooting
”No results found”
- Check that the index file exists and is readable
- Verify the query is meaningful (not too short or generic)
- Lower similarity_threshold if set too high
- Ensure documents were actually indexed (check with
sw-search validate)
Poor result relevance
- Try different chunking strategies
- Increase count to see more results
- Review source documents for quality
- Consider adding tags to filter by category
Slow search performance
- For large indexes, use pgvector instead of SQLite
- Reduce count if you don’t need many results
- Consider a remote search server for shared access
Index file issues
- Validate with
sw-search validate knowledge.swsearch - Rebuild if corrupted
- Check file permissions
Search Best Practices
Index Building
- Use markdown chunking for documentation
- Keep chunks reasonably sized (5-10 sentences)
- Add meaningful tags for filtering
- Rebuild indexes when source docs change
- Test search quality after building
- Version your indexes with your documentation
Agent Configuration
- Set count=3-5 for most use cases
- Use similarity_threshold to filter noise
- Give descriptive tool_name and tool_description
- Tell AI when/how to use search in the prompt
- Handle “no results” gracefully in your prompt
Production
- Use pgvector for high-volume deployments
- Consider remote search server for shared indexes
- Monitor search latency and result quality
- Automate index rebuilding when docs change
- Log search queries to understand user needs