Cli Sw Search
sw-search CLI
Command-line tool for building, searching, and managing vector search indexes for AI agent knowledge bases.
Overview
The sw-search tool builds vector search indexes from documents for use with the native_vector_search skill.
Capabilities:
- Build indexes from documents (MD, TXT, PDF, DOCX, RST, PY)
- Multiple chunking strategies for different content types
- SQLite and PostgreSQL/pgvector storage backends
- Interactive search shell for index exploration
- Export chunks to JSON for review or external processing
- Migrate indexes between backends
- Search via remote API endpoints
Architecture
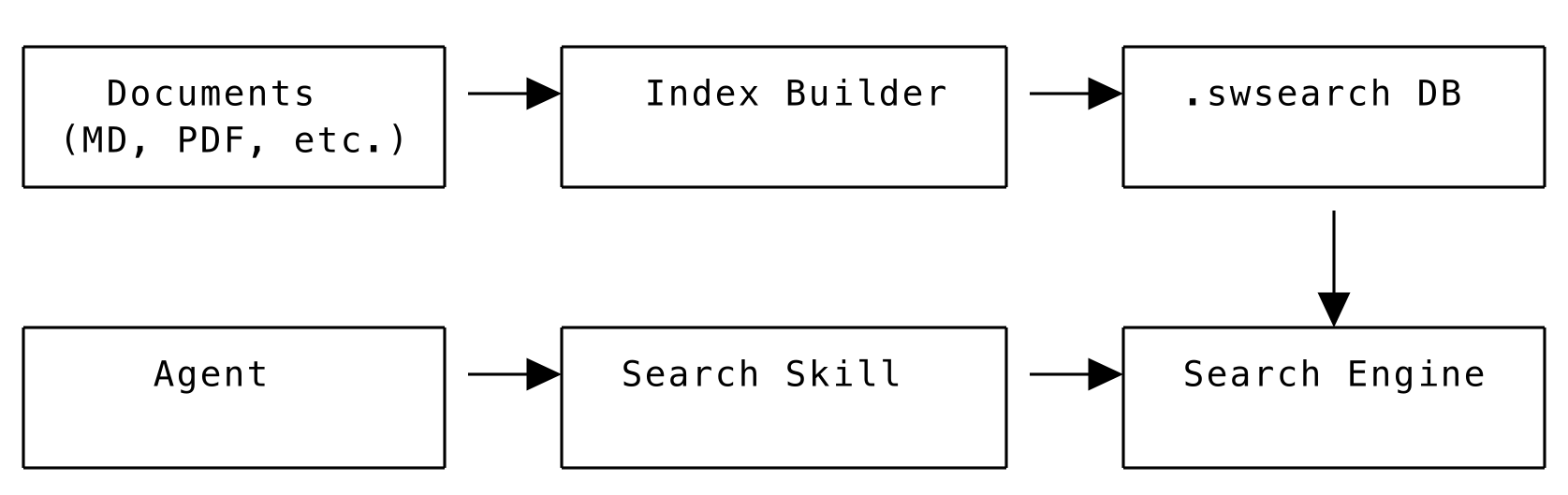
The system provides:
- Offline Search: No external API calls or internet required
- Hybrid Search: Combines vector similarity and keyword search
- Smart Chunking: Intelligent document segmentation with context preservation
- Advanced Query Processing: NLP-enhanced query understanding
- Flexible Deployment: Local embedded mode or remote server mode
- SQLite Storage: Portable
.swsearchindex files
Command Modes
sw-search operates in five modes:
Quick Start
Building Indexes
Index Structure
Each .swsearch file is a SQLite database containing:
- Document chunks with embeddings and metadata
- Full-text search index (SQLite FTS5) for keyword search
- Configuration and model information
- Synonym cache for query expansion
This portable format allows you to build indexes once and distribute them with your agents.
Basic Usage
Build Options
Chunking Strategies
Choose the right strategy for your content:
Sentence Chunking (Default)
Groups sentences together:
Sliding Window Chunking
Fixed-size chunks with overlap:
Paragraph Chunking
Splits on double newlines:
Page Chunking
Best for PDFs:
Semantic Chunking
Groups semantically similar sentences:
Topic Chunking
Detects topic changes:
QA Chunking
Optimized for question-answering:
Markdown Chunking
The markdown strategy is specifically designed for documentation that contains code examples. It understands markdown structure and adds rich metadata for better search results.
Features:
- Header-based chunking: Splits at markdown headers (h1, h2, h3…) for natural boundaries
- Code block detection: Identifies fenced code blocks and extracts language (
python,bash, etc.) - Smart tagging: Adds
"code"tags to chunks with code, plus language-specific tags - Section hierarchy: Preserves full path (e.g., “API Reference > AgentBase > Methods”)
- Code protection: Never splits inside code blocks
- Metadata enrichment: Header levels stored as searchable metadata
Example Metadata:
Search Benefits:
When users search for “example code Python”:
- Chunks with code blocks get automatic 20% boost
- Python-specific code gets language match bonus
- Vector similarity provides primary semantic ranking
- Metadata tags provide confirmation signals
- Results blend semantic + structural relevance
Best Used With:
- API documentation with code examples
- Tutorial content with inline code
- Technical guides with multiple languages
- README files with usage examples
Usage with pgvector:
JSON Chunking
The json strategy allows you to provide pre-chunked content in a structured format. This is useful when you need custom control over how documents are split and indexed.
Expected JSON Format:
Usage:
Best Used For:
- API documentation with complex structure
- Documents that need custom parsing logic
- Preserving specific metadata relationships
- Integration with external preprocessing tools
Model Selection
Choose embedding model based on speed vs quality:
File Filtering
Tags and Metadata
Add tags during build for filtered searching:
Searching Indexes
Basic Search
Search Options
Output Formats
Filter by Tags
Interactive Search Shell
Load index once and search multiple times:
Shell commands:
Example session:
PostgreSQL/pgvector Backend
The search system supports multiple storage backends. Choose based on your deployment needs:
Backend Comparison
SQLite Backend (Default):
- File-based
.swsearchindexes - Portable single-file format
- No external dependencies
- Best for: Single-agent deployments, development, small to medium datasets
pgvector Backend:
- Server-based PostgreSQL storage
- Efficient similarity search with IVFFlat/HNSW indexes
- Multiple agents can share the same knowledge base
- Real-time updates without rebuilding
- Best for: Production deployments, multi-agent systems, large datasets
Building with pgvector
Search pgvector Collection
Migration
Migrate indexes between backends:
Migration Options
Local vs Remote Modes
The search skill supports both local and remote operation modes.
Local Mode (Default)
Searches are performed directly in the agent process using the embedded search engine.
Pros:
- Faster (no network latency)
- Works offline
- Simple deployment
- Lower operational complexity
Cons:
- Higher memory usage per agent
- Index files must be distributed with each agent
- Updates require redeploying agents
Configuration in Agent:
Remote Mode
Searches are performed via HTTP API to a centralized search server.
Pros:
- Lower memory usage per agent
- Centralized index management
- Easy updates without redeploying agents
- Better scalability for multiple agents
- Shared resources
Cons:
- Network dependency
- Additional infrastructure complexity
- Potential latency
Configuration in Agent:
Automatic Mode Detection
The skill automatically detects which mode to use:
- If
remote_urlis provided → Remote mode - If
index_fileis provided → Local mode - Remote mode takes priority if both are specified
Running a Remote Search Server
- Start the search server:
-
The server provides HTTP API:
POST /search- Search the indexesGET /health- Health check and available indexesPOST /reload_index- Add or reload an index
-
Test the API:
Remote Search CLI
Search via remote API endpoint from the command line:
Remote Options
Validation
Verify index integrity:
Output:
JSON Export
Export chunks for review or external processing:
NLP Backend Selection
Choose NLP backend for processing:
Complete Configuration Example
Using with Skills
After building an index, use it with the native_vector_search skill:
Output Formats
Installation Requirements
The search system uses optional dependencies to keep the base SDK lightweight. Choose the installation option that fits your needs:
Basic Search (~500MB)
Includes:
- Core search functionality
- Sentence transformers for embeddings
- SQLite FTS5 for keyword search
- Basic document processing (text, markdown)
Full Document Processing (~600MB)
Adds:
- PDF processing (PyPDF2)
- DOCX processing (python-docx)
- HTML processing (BeautifulSoup4)
- Additional file format support
Advanced NLP Features (~700MB)
Adds:
- spaCy for advanced text processing
- NLTK for linguistic analysis
- Enhanced query preprocessing
- Language detection
Additional Setup Required:
Performance Note: Advanced NLP features provide significantly better query understanding, synonym expansion, and search relevance, but are 2-3x slower than basic search. Only recommended if you have sufficient CPU power and can tolerate longer response times.
All Search Features (~700MB)
Includes everything above.
Additional Setup Required:
Query-Only Mode (~400MB)
For agents that only need to query pre-built indexes without building new ones.
PostgreSQL Vector Support
Adds PostgreSQL with pgvector extension support for production deployments.
NLP Backend Selection
You can choose which NLP backend to use for query processing:
Configure via --index-nlp-backend (build) or --query-nlp-backend (search) flags.
API Reference
For programmatic access to the search system, use the Python API directly.
SearchEngine Class
IndexBuilder Class
Troubleshooting
Related Documentation
- native_vector_search Skill - Using search indexes in agents
- Skills Overview - Adding skills to agents
- DataSphere Integration - Cloud-based search alternative