***
id: fe965e69-bac0-4bfe-8531-ed87e2f0487f
title: Cli Sw Search
sidebar-title: Cli Sw Search
slug: /python/reference/cli-sw-search
max-toc-depth: 3
----------------
## sw-search CLI
Command-line tool for building, searching, and managing vector search indexes for AI agent knowledge bases.
### Overview
The `sw-search` tool builds vector search indexes from documents for use with the native\_vector\_search skill.
**Capabilities:**
* Build indexes from documents (MD, TXT, PDF, DOCX, RST, PY)
* Multiple chunking strategies for different content types
* SQLite and PostgreSQL/pgvector storage backends
* Interactive search shell for index exploration
* Export chunks to JSON for review or external processing
* Migrate indexes between backends
* Search via remote API endpoints
### Architecture
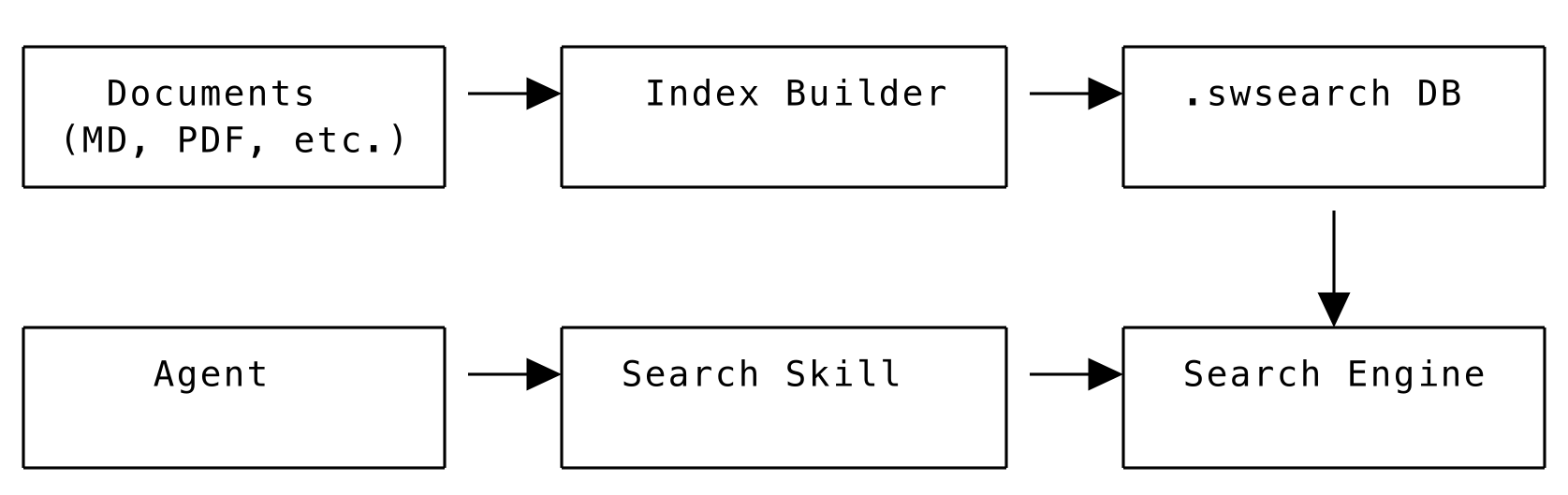 The system provides:
* **Offline Search**: No external API calls or internet required
* **Hybrid Search**: Combines vector similarity and keyword search
* **Smart Chunking**: Intelligent document segmentation with context preservation
* **Advanced Query Processing**: NLP-enhanced query understanding
* **Flexible Deployment**: Local embedded mode or remote server mode
* **SQLite Storage**: Portable `.swsearch` index files
### Command Modes
sw-search operates in five modes:
| Mode | Syntax | Purpose |
| -------- | ----------------------------- | ------------------------ |
| build | `sw-search ./docs` | Build search index |
| search | `sw-search search FILE QUERY` | Search existing index |
| validate | `sw-search validate FILE` | Validate index integrity |
| migrate | `sw-search migrate FILE` | Migrate between backends |
| remote | `sw-search remote URL QUERY` | Search via remote API |
### Quick Start
```bash
## Build index from documentation
sw-search ./docs --output knowledge.swsearch
## Search the index
sw-search search knowledge.swsearch "how to create an agent"
## Interactive search shell
sw-search search knowledge.swsearch --shell
## Validate index
sw-search validate knowledge.swsearch
```
### Building Indexes
#### Index Structure
Each `.swsearch` file is a SQLite database containing:
* **Document chunks** with embeddings and metadata
* **Full-text search index** (SQLite FTS5) for keyword search
* **Configuration** and model information
* **Synonym cache** for query expansion
This portable format allows you to build indexes once and distribute them with your agents.
#### Basic Usage
```bash
## Build from single directory
sw-search ./docs
## Build from multiple directories
sw-search ./docs ./examples --file-types md,txt,py
## Build from individual files
sw-search README.md ./docs/guide.md ./src/main.py
## Mixed sources (directories and files)
sw-search ./docs README.md ./examples specific_file.txt
## Specify output file
sw-search ./docs --output ./knowledge.swsearch
```
#### Build Options
| Option | Default | Description |
| ------------------ | ---------------- | --------------------------- |
| `--output FILE` | sources.swsearch | Output file or collection |
| `--output-dir DIR` | (none) | Output directory |
| `--output-format` | index | Output: index or json |
| `--backend` | sqlite | Storage: sqlite or pgvector |
| `--file-types` | md,txt,rst | Comma-separated extensions |
| `--exclude` | (none) | Glob patterns to exclude |
| `--languages` | en | Language codes |
| `--tags` | (none) | Tags for all chunks |
| `--validate` | false | Validate after building |
| `--verbose` | false | Detailed output |
### Chunking Strategies
Choose the right strategy for your content:
| Strategy | Best For | Key Options |
| --------- | ------------------------------ | -------------------------------- |
| sentence | General prose, articles | `--max-sentences-per-chunk` |
| sliding | Code, technical documentation | `--chunk-size`, `--overlap-size` |
| paragraph | Structured documents | (none) |
| page | PDFs with distinct pages | (none) |
| semantic | Coherent topic grouping | `--semantic-threshold` |
| topic | Long documents by subject | `--topic-threshold` |
| qa | Question-answering apps | (none) |
| markdown | Documentation with code blocks | (preserves structure) |
| json | Pre-chunked content | (none) |
#### Sentence Chunking (Default)
Groups sentences together:
```bash
## Default: 5 sentences per chunk
sw-search ./docs --chunking-strategy sentence
## Custom sentence count
sw-search ./docs \
--chunking-strategy sentence \
--max-sentences-per-chunk 10
## Split on multiple newlines
sw-search ./docs \
--chunking-strategy sentence \
--max-sentences-per-chunk 8 \
--split-newlines 2
```
#### Sliding Window Chunking
Fixed-size chunks with overlap:
```bash
sw-search ./docs \
--chunking-strategy sliding \
--chunk-size 100 \
--overlap-size 20
```
#### Paragraph Chunking
Splits on double newlines:
```bash
sw-search ./docs \
--chunking-strategy paragraph \
--file-types md,txt,rst
```
#### Page Chunking
Best for PDFs:
```bash
sw-search ./docs \
--chunking-strategy page \
--file-types pdf
```
#### Semantic Chunking
Groups semantically similar sentences:
```bash
sw-search ./docs \
--chunking-strategy semantic \
--semantic-threshold 0.6
```
#### Topic Chunking
Detects topic changes:
```bash
sw-search ./docs \
--chunking-strategy topic \
--topic-threshold 0.2
```
#### QA Chunking
Optimized for question-answering:
```bash
sw-search ./docs --chunking-strategy qa
```
#### Markdown Chunking
The `markdown` strategy is specifically designed for documentation that contains code examples. It understands markdown structure and adds rich metadata for better search results.
```bash
sw-search ./docs \
--chunking-strategy markdown \
--file-types md
```
**Features:**
* **Header-based chunking**: Splits at markdown headers (h1, h2, h3...) for natural boundaries
* **Code block detection**: Identifies fenced code blocks and extracts language (`python, `bash, etc.)
* **Smart tagging**: Adds `"code"` tags to chunks with code, plus language-specific tags
* **Section hierarchy**: Preserves full path (e.g., "API Reference > AgentBase > Methods")
* **Code protection**: Never splits inside code blocks
* **Metadata enrichment**: Header levels stored as searchable metadata
**Example Metadata:**
```json
{
"chunk_type": "markdown",
"h1": "API Reference",
"h2": "AgentBase",
"h3": "add_skill Method",
"has_code": true,
"code_languages": ["python", "bash"],
"tags": ["code", "code:python", "code:bash", "depth:3"]
}
```
**Search Benefits:**
When users search for "example code Python":
* Chunks with code blocks get automatic 20% boost
* Python-specific code gets language match bonus
* Vector similarity provides primary semantic ranking
* Metadata tags provide confirmation signals
* Results blend semantic + structural relevance
**Best Used With:**
* API documentation with code examples
* Tutorial content with inline code
* Technical guides with multiple languages
* README files with usage examples
**Usage with pgvector:**
```bash
sw-search ./docs \
--backend pgvector \
--connection-string "postgresql://user:pass@localhost:5432/db" \
--output docs_collection \
--chunking-strategy markdown
```
#### JSON Chunking
The `json` strategy allows you to provide pre-chunked content in a structured format. This is useful when you need custom control over how documents are split and indexed.
**Expected JSON Format:**
```json
{
"chunks": [
{
"chunk_id": "unique_id",
"type": "content",
"content": "The actual text content",
"metadata": {
"section": "Introduction",
"url": "https://example.com/docs/intro",
"custom_field": "any_value"
},
"tags": ["intro", "getting-started"]
}
]
}
```
**Usage:**
```bash
## First preprocess your documents into JSON chunks
python your_preprocessor.py input.txt -o chunks.json
## Then build the index using JSON strategy
sw-search chunks.json --chunking-strategy json --file-types json
```
**Best Used For:**
* API documentation with complex structure
* Documents that need custom parsing logic
* Preserving specific metadata relationships
* Integration with external preprocessing tools
### Model Selection
Choose embedding model based on speed vs quality:
| Alias | Model | Dims | Speed | Quality |
| ----- | ----------------- | ---- | ----- | ------- |
| mini | all-MiniLM-L6-v2 | 384 | \~5x | Good |
| base | all-mpnet-base-v2 | 768 | 1x | High |
| large | all-mpnet-base-v2 | 768 | 1x | Highest |
```bash
## Fast model (default, recommended for most cases)
sw-search ./docs --model mini
## Balanced model
sw-search ./docs --model base
## Best quality
sw-search ./docs --model large
## Full model name
sw-search ./docs --model sentence-transformers/all-mpnet-base-v2
```
### File Filtering
```bash
## Specific file types
sw-search ./docs --file-types md,txt,rst,py
## Exclude patterns
sw-search ./docs --exclude "**/test/**,**/__pycache__/**,**/.git/**"
## Language filtering
sw-search ./docs --languages en,es,fr
```
### Tags and Metadata
Add tags during build for filtered searching:
```bash
## Add tags to all chunks
sw-search ./docs --tags documentation,api,v2
## Filter by tags when searching
sw-search search index.swsearch "query" --tags documentation
```
### Searching Indexes
#### Basic Search
```bash
## Search with query
sw-search search knowledge.swsearch "how to create an agent"
## Limit results
sw-search search knowledge.swsearch "API reference" --count 3
## Verbose output with scores
sw-search search knowledge.swsearch "configuration" --verbose
```
#### Search Options
| Option | Default | Description |
| ---------------------- | ------- | -------------------------------- |
| `--count` | 5 | Number of results |
| `--distance-threshold` | 0.0 | Minimum similarity score |
| `--tags` | (none) | Filter by tags |
| `--query-nlp-backend` | nltk | NLP backend: nltk or spacy |
| `--keyword-weight` | (auto) | Manual keyword weight (0.0-1.0) |
| `--model` | (index) | Override embedding model |
| `--json` | false | Output as JSON |
| `--no-content` | false | Hide content, show metadata only |
| `--verbose` | false | Detailed output |
#### Output Formats
```bash
## Human-readable (default)
sw-search search knowledge.swsearch "query"
## JSON output
sw-search search knowledge.swsearch "query" --json
## Metadata only
sw-search search knowledge.swsearch "query" --no-content
## Full verbose output
sw-search search knowledge.swsearch "query" --verbose
```
#### Filter by Tags
```bash
## Single tag
sw-search search knowledge.swsearch "functions" --tags documentation
## Multiple tags
sw-search search knowledge.swsearch "API" --tags api,reference
```
### Interactive Search Shell
Load index once and search multiple times:
```bash
sw-search search knowledge.swsearch --shell
```
Shell commands:
| Command | Description |
| ----------------- | --------------------- |
| `help` | Show help |
| `exit`/`quit`/`q` | Exit shell |
| `count=N` | Set result count |
| `tags=tag1,tag2` | Set tag filter |
| `verbose` | Toggle verbose output |
| `` | Search for query |
Example session:
```
$ sw-search search knowledge.swsearch --shell
Search Shell - Index: knowledge.swsearch
Backend: sqlite
Index contains 1523 chunks from 47 files
Model: sentence-transformers/all-MiniLM-L6-v2
Type 'exit' or 'quit' to leave, 'help' for options
------------------------------------------------------------
search> how to create an agent
Found 5 result(s) for 'how to create an agent' (0.034s):
...
search> count=3
Result count set to: 3
search> SWAIG functions
Found 3 result(s) for 'SWAIG functions' (0.028s):
...
search> exit
Goodbye!
```
### PostgreSQL/pgvector Backend
The search system supports multiple storage backends. Choose based on your deployment needs:
#### Backend Comparison
| Feature | SQLite | pgvector |
| ---------------------------- | ---------------- | --------------------- |
| Setup complexity | None | Requires PostgreSQL |
| Scalability | Limited | Excellent |
| Concurrent access | Poor | Excellent |
| Update capability | Rebuild required | Real-time |
| Performance (small datasets) | Excellent | Good |
| Performance (large datasets) | Poor | Excellent |
| Deployment | File copy | Database connection |
| Multi-agent support | Separate copies | Shared knowledge base |
**SQLite Backend (Default):**
* File-based `.swsearch` indexes
* Portable single-file format
* No external dependencies
* Best for: Single-agent deployments, development, small to medium datasets
**pgvector Backend:**
* Server-based PostgreSQL storage
* Efficient similarity search with IVFFlat/HNSW indexes
* Multiple agents can share the same knowledge base
* Real-time updates without rebuilding
* Best for: Production deployments, multi-agent systems, large datasets
#### Building with pgvector
```bash
## Build to pgvector
sw-search ./docs \
--backend pgvector \
--connection-string "postgresql://user:pass@localhost:5432/knowledge" \
--output docs_collection
## With markdown strategy
sw-search ./docs \
--backend pgvector \
--connection-string "postgresql://user:pass@localhost:5432/knowledge" \
--output docs_collection \
--chunking-strategy markdown
## Overwrite existing collection
sw-search ./docs \
--backend pgvector \
--connection-string "postgresql://user:pass@localhost:5432/knowledge" \
--output docs_collection \
--overwrite
```
#### Search pgvector Collection
```bash
sw-search search docs_collection "how to create an agent" \
--backend pgvector \
--connection-string "postgresql://user:pass@localhost/knowledge"
```
### Migration
Migrate indexes between backends:
```bash
## Get index information
sw-search migrate --info ./docs.swsearch
## Migrate SQLite to pgvector
sw-search migrate ./docs.swsearch --to-pgvector \
--connection-string "postgresql://user:pass@localhost/db" \
--collection-name docs_collection
## Migrate with overwrite
sw-search migrate ./docs.swsearch --to-pgvector \
--connection-string "postgresql://user:pass@localhost/db" \
--collection-name docs_collection \
--overwrite
```
#### Migration Options
| Option | Description |
| --------------------- | ------------------------------------ |
| `--info` | Show index information |
| `--to-pgvector` | Migrate SQLite to pgvector |
| `--to-sqlite` | Migrate pgvector to SQLite (planned) |
| `--connection-string` | PostgreSQL connection string |
| `--collection-name` | Target collection name |
| `--overwrite` | Overwrite existing collection |
| `--batch-size` | Chunks per batch (default: 100) |
### Local vs Remote Modes
The search skill supports both local and remote operation modes.
#### Local Mode (Default)
Searches are performed directly in the agent process using the embedded search engine.
**Pros:**
* Faster (no network latency)
* Works offline
* Simple deployment
* Lower operational complexity
**Cons:**
* Higher memory usage per agent
* Index files must be distributed with each agent
* Updates require redeploying agents
**Configuration in Agent:**
```python
self.add_skill("native_vector_search", {
"tool_name": "search_docs",
"index_file": "docs.swsearch", # Local file
"nlp_backend": "nltk"
})
```
#### Remote Mode
Searches are performed via HTTP API to a centralized search server.
**Pros:**
* Lower memory usage per agent
* Centralized index management
* Easy updates without redeploying agents
* Better scalability for multiple agents
* Shared resources
**Cons:**
* Network dependency
* Additional infrastructure complexity
* Potential latency
**Configuration in Agent:**
```python
self.add_skill("native_vector_search", {
"tool_name": "search_docs",
"remote_url": "http://localhost:8001", # Search server
"index_name": "docs",
"nlp_backend": "nltk"
})
```
#### Automatic Mode Detection
The skill automatically detects which mode to use:
* If `remote_url` is provided → Remote mode
* If `index_file` is provided → Local mode
* Remote mode takes priority if both are specified
#### Running a Remote Search Server
1. **Start the search server:**
```bash
python examples/search_server_standalone.py
```
2. **The server provides HTTP API:**
* `POST /search` - Search the indexes
* `GET /health` - Health check and available indexes
* `POST /reload_index` - Add or reload an index
3. **Test the API:**
```bash
curl -X POST "http://localhost:8001/search" \
-H "Content-Type: application/json" \
-d '{"query": "how to create an agent", "index_name": "docs", "count": 3}'
```
### Remote Search CLI
Search via remote API endpoint from the command line:
```bash
## Basic remote search
sw-search remote http://localhost:8001 "how to create an agent" \
--index-name docs
## With options
sw-search remote localhost:8001 "API reference" \
--index-name docs \
--count 3 \
--verbose
## JSON output
sw-search remote localhost:8001 "query" \
--index-name docs \
--json
```
#### Remote Options
| Option | Default | Description |
| ---------------------- | ---------- | --------------------------- |
| `--index-name` | (required) | Name of the index to search |
| `--count` | 5 | Number of results |
| `--distance-threshold` | 0.0 | Minimum similarity score |
| `--tags` | (none) | Filter by tags |
| `--timeout` | 30 | Request timeout in seconds |
| `--json` | false | Output as JSON |
| `--no-content` | false | Hide content |
| `--verbose` | false | Detailed output |
### Validation
Verify index integrity:
```bash
## Validate index
sw-search validate ./docs.swsearch
## Verbose validation
sw-search validate ./docs.swsearch --verbose
```
Output:
```
✓ Index is valid: ./docs.swsearch
Chunks: 1523
Files: 47
Configuration:
embedding_model: sentence-transformers/all-MiniLM-L6-v2
embedding_dimensions: 384
chunking_strategy: markdown
created_at: 2025-01-15T10:30:00
```
### JSON Export
Export chunks for review or external processing:
```bash
## Export to single JSON file
sw-search ./docs \
--output-format json \
--output all_chunks.json
## Export to directory (one file per source)
sw-search ./docs \
--output-format json \
--output-dir ./chunks/
## Build index from exported JSON
sw-search ./chunks/ \
--chunking-strategy json \
--file-types json \
--output final.swsearch
```
### NLP Backend Selection
Choose NLP backend for processing:
| Backend | Speed | Quality | Install Size |
| ------- | ------ | ------- | ----------------------------------------------------- |
| nltk | Fast | Good | Included |
| spacy | Slower | Better | Requires: `pip install signalwire-agents[search-nlp]` |
```bash
## Index with NLTK (default)
sw-search ./docs --index-nlp-backend nltk
## Index with spaCy (better quality)
sw-search ./docs --index-nlp-backend spacy
## Query with NLTK
sw-search search index.swsearch "query" --query-nlp-backend nltk
## Query with spaCy
sw-search search index.swsearch "query" --query-nlp-backend spacy
```
### Complete Configuration Example
```bash
sw-search ./docs ./examples README.md \
--output ./knowledge.swsearch \
--chunking-strategy sentence \
--max-sentences-per-chunk 8 \
--file-types md,txt,rst,py \
--exclude "**/test/**,**/__pycache__/**" \
--languages en,es,fr \
--model sentence-transformers/all-mpnet-base-v2 \
--tags documentation,api \
--index-nlp-backend nltk \
--validate \
--verbose
```
### Using with Skills
After building an index, use it with the native\_vector\_search skill:
```python
from signalwire_agents import AgentBase
agent = AgentBase(name="search-agent")
## Add search skill with built index
agent.add_skill("native_vector_search", {
"index_path": "./knowledge.swsearch",
"tool_name": "search_docs",
"tool_description": "Search the documentation"
})
```
### Output Formats
| Format | Extension | Description |
| -------- | ---------- | ------------------------------------- |
| swsearch | .swsearch | SQLite-based portable index (default) |
| json | .json | JSON export of chunks |
| pgvector | (database) | PostgreSQL with pgvector extension |
### Installation Requirements
The search system uses optional dependencies to keep the base SDK lightweight. Choose the installation option that fits your needs:
#### Basic Search (\~500MB)
```bash
pip install "signalwire-agents[search]"
```
**Includes:**
* Core search functionality
* Sentence transformers for embeddings
* SQLite FTS5 for keyword search
* Basic document processing (text, markdown)
#### Full Document Processing (\~600MB)
```bash
pip install "signalwire-agents[search-full]"
```
**Adds:**
* PDF processing (PyPDF2)
* DOCX processing (python-docx)
* HTML processing (BeautifulSoup4)
* Additional file format support
#### Advanced NLP Features (\~700MB)
```bash
pip install "signalwire-agents[search-nlp]"
```
**Adds:**
* spaCy for advanced text processing
* NLTK for linguistic analysis
* Enhanced query preprocessing
* Language detection
**Additional Setup Required:**
```bash
python -m spacy download en_core_web_sm
```
**Performance Note:** Advanced NLP features provide significantly better query understanding, synonym expansion, and search relevance, but are 2-3x slower than basic search. Only recommended if you have sufficient CPU power and can tolerate longer response times.
#### All Search Features (\~700MB)
```bash
pip install "signalwire-agents[search-all]"
```
**Includes everything above.**
**Additional Setup Required:**
```bash
python -m spacy download en_core_web_sm
```
#### Query-Only Mode (\~400MB)
```bash
pip install "signalwire-agents[search-queryonly]"
```
For agents that only need to query pre-built indexes without building new ones.
#### PostgreSQL Vector Support
```bash
pip install "signalwire-agents[pgvector]"
```
Adds PostgreSQL with pgvector extension support for production deployments.
#### NLP Backend Selection
You can choose which NLP backend to use for query processing:
| Backend | Speed | Quality | Notes |
| ------- | -------------------- | ------- | ----------------------------------------- |
| nltk | Fast (\~50-100ms) | Good | Default, good for most use cases |
| spacy | Slower (\~150-300ms) | Better | Better POS tagging and entity recognition |
Configure via `--index-nlp-backend` (build) or `--query-nlp-backend` (search) flags.
### API Reference
For programmatic access to the search system, use the Python API directly.
#### SearchEngine Class
```python
from signalwire_agents.search import SearchEngine
## Load an index
engine = SearchEngine("docs.swsearch")
## Perform search
results = engine.search(
query_vector=[...], # Optional: pre-computed query vector
enhanced_text="search query", # Enhanced query text
count=5, # Number of results
similarity_threshold=0.0, # Minimum similarity score
tags=["documentation"] # Filter by tags
)
## Get index statistics
stats = engine.get_stats()
print(f"Total chunks: {stats['total_chunks']}")
print(f"Total files: {stats['total_files']}")
```
#### IndexBuilder Class
```python
from signalwire_agents.search import IndexBuilder
## Create index builder
builder = IndexBuilder(
model_name="sentence-transformers/all-mpnet-base-v2",
chunk_size=500,
chunk_overlap=50,
verbose=True
)
## Build index
builder.build_index(
source_dir="./docs",
output_file="docs.swsearch",
file_types=["md", "txt"],
exclude_patterns=["**/test/**"],
tags=["documentation"]
)
```
### Troubleshooting
| Issue | Solution |
| --------------------------- | -------------------------------------------- |
| Search not available | `pip install signalwire-agents[search]` |
| pgvector errors | `pip install signalwire-agents[pgvector]` |
| PDF processing fails | `pip install signalwire-agents[search-full]` |
| spaCy not found | `pip install signalwire-agents[search-nlp]` |
| No results found | Try different chunking strategy |
| Poor search quality | Use `--model base` or larger chunks |
| Index too large | Use `--model mini`, reduce file types |
| Connection refused (remote) | Check search server is running |
### Related Documentation
* [native\_vector\_search Skill](/docs/agents-sdk/python/guides/builtin-skills#native_vector_search) - Using search indexes in agents
* [Skills Overview](/docs/agents-sdk/python/guides/understanding-skills) - Adding skills to agents
* [DataSphere Integration](/docs/agents-sdk/python/guides/builtin-skills#datasphere) - Cloud-based search alternative
The system provides:
* **Offline Search**: No external API calls or internet required
* **Hybrid Search**: Combines vector similarity and keyword search
* **Smart Chunking**: Intelligent document segmentation with context preservation
* **Advanced Query Processing**: NLP-enhanced query understanding
* **Flexible Deployment**: Local embedded mode or remote server mode
* **SQLite Storage**: Portable `.swsearch` index files
### Command Modes
sw-search operates in five modes:
| Mode | Syntax | Purpose |
| -------- | ----------------------------- | ------------------------ |
| build | `sw-search ./docs` | Build search index |
| search | `sw-search search FILE QUERY` | Search existing index |
| validate | `sw-search validate FILE` | Validate index integrity |
| migrate | `sw-search migrate FILE` | Migrate between backends |
| remote | `sw-search remote URL QUERY` | Search via remote API |
### Quick Start
```bash
## Build index from documentation
sw-search ./docs --output knowledge.swsearch
## Search the index
sw-search search knowledge.swsearch "how to create an agent"
## Interactive search shell
sw-search search knowledge.swsearch --shell
## Validate index
sw-search validate knowledge.swsearch
```
### Building Indexes
#### Index Structure
Each `.swsearch` file is a SQLite database containing:
* **Document chunks** with embeddings and metadata
* **Full-text search index** (SQLite FTS5) for keyword search
* **Configuration** and model information
* **Synonym cache** for query expansion
This portable format allows you to build indexes once and distribute them with your agents.
#### Basic Usage
```bash
## Build from single directory
sw-search ./docs
## Build from multiple directories
sw-search ./docs ./examples --file-types md,txt,py
## Build from individual files
sw-search README.md ./docs/guide.md ./src/main.py
## Mixed sources (directories and files)
sw-search ./docs README.md ./examples specific_file.txt
## Specify output file
sw-search ./docs --output ./knowledge.swsearch
```
#### Build Options
| Option | Default | Description |
| ------------------ | ---------------- | --------------------------- |
| `--output FILE` | sources.swsearch | Output file or collection |
| `--output-dir DIR` | (none) | Output directory |
| `--output-format` | index | Output: index or json |
| `--backend` | sqlite | Storage: sqlite or pgvector |
| `--file-types` | md,txt,rst | Comma-separated extensions |
| `--exclude` | (none) | Glob patterns to exclude |
| `--languages` | en | Language codes |
| `--tags` | (none) | Tags for all chunks |
| `--validate` | false | Validate after building |
| `--verbose` | false | Detailed output |
### Chunking Strategies
Choose the right strategy for your content:
| Strategy | Best For | Key Options |
| --------- | ------------------------------ | -------------------------------- |
| sentence | General prose, articles | `--max-sentences-per-chunk` |
| sliding | Code, technical documentation | `--chunk-size`, `--overlap-size` |
| paragraph | Structured documents | (none) |
| page | PDFs with distinct pages | (none) |
| semantic | Coherent topic grouping | `--semantic-threshold` |
| topic | Long documents by subject | `--topic-threshold` |
| qa | Question-answering apps | (none) |
| markdown | Documentation with code blocks | (preserves structure) |
| json | Pre-chunked content | (none) |
#### Sentence Chunking (Default)
Groups sentences together:
```bash
## Default: 5 sentences per chunk
sw-search ./docs --chunking-strategy sentence
## Custom sentence count
sw-search ./docs \
--chunking-strategy sentence \
--max-sentences-per-chunk 10
## Split on multiple newlines
sw-search ./docs \
--chunking-strategy sentence \
--max-sentences-per-chunk 8 \
--split-newlines 2
```
#### Sliding Window Chunking
Fixed-size chunks with overlap:
```bash
sw-search ./docs \
--chunking-strategy sliding \
--chunk-size 100 \
--overlap-size 20
```
#### Paragraph Chunking
Splits on double newlines:
```bash
sw-search ./docs \
--chunking-strategy paragraph \
--file-types md,txt,rst
```
#### Page Chunking
Best for PDFs:
```bash
sw-search ./docs \
--chunking-strategy page \
--file-types pdf
```
#### Semantic Chunking
Groups semantically similar sentences:
```bash
sw-search ./docs \
--chunking-strategy semantic \
--semantic-threshold 0.6
```
#### Topic Chunking
Detects topic changes:
```bash
sw-search ./docs \
--chunking-strategy topic \
--topic-threshold 0.2
```
#### QA Chunking
Optimized for question-answering:
```bash
sw-search ./docs --chunking-strategy qa
```
#### Markdown Chunking
The `markdown` strategy is specifically designed for documentation that contains code examples. It understands markdown structure and adds rich metadata for better search results.
```bash
sw-search ./docs \
--chunking-strategy markdown \
--file-types md
```
**Features:**
* **Header-based chunking**: Splits at markdown headers (h1, h2, h3...) for natural boundaries
* **Code block detection**: Identifies fenced code blocks and extracts language (`python, `bash, etc.)
* **Smart tagging**: Adds `"code"` tags to chunks with code, plus language-specific tags
* **Section hierarchy**: Preserves full path (e.g., "API Reference > AgentBase > Methods")
* **Code protection**: Never splits inside code blocks
* **Metadata enrichment**: Header levels stored as searchable metadata
**Example Metadata:**
```json
{
"chunk_type": "markdown",
"h1": "API Reference",
"h2": "AgentBase",
"h3": "add_skill Method",
"has_code": true,
"code_languages": ["python", "bash"],
"tags": ["code", "code:python", "code:bash", "depth:3"]
}
```
**Search Benefits:**
When users search for "example code Python":
* Chunks with code blocks get automatic 20% boost
* Python-specific code gets language match bonus
* Vector similarity provides primary semantic ranking
* Metadata tags provide confirmation signals
* Results blend semantic + structural relevance
**Best Used With:**
* API documentation with code examples
* Tutorial content with inline code
* Technical guides with multiple languages
* README files with usage examples
**Usage with pgvector:**
```bash
sw-search ./docs \
--backend pgvector \
--connection-string "postgresql://user:pass@localhost:5432/db" \
--output docs_collection \
--chunking-strategy markdown
```
#### JSON Chunking
The `json` strategy allows you to provide pre-chunked content in a structured format. This is useful when you need custom control over how documents are split and indexed.
**Expected JSON Format:**
```json
{
"chunks": [
{
"chunk_id": "unique_id",
"type": "content",
"content": "The actual text content",
"metadata": {
"section": "Introduction",
"url": "https://example.com/docs/intro",
"custom_field": "any_value"
},
"tags": ["intro", "getting-started"]
}
]
}
```
**Usage:**
```bash
## First preprocess your documents into JSON chunks
python your_preprocessor.py input.txt -o chunks.json
## Then build the index using JSON strategy
sw-search chunks.json --chunking-strategy json --file-types json
```
**Best Used For:**
* API documentation with complex structure
* Documents that need custom parsing logic
* Preserving specific metadata relationships
* Integration with external preprocessing tools
### Model Selection
Choose embedding model based on speed vs quality:
| Alias | Model | Dims | Speed | Quality |
| ----- | ----------------- | ---- | ----- | ------- |
| mini | all-MiniLM-L6-v2 | 384 | \~5x | Good |
| base | all-mpnet-base-v2 | 768 | 1x | High |
| large | all-mpnet-base-v2 | 768 | 1x | Highest |
```bash
## Fast model (default, recommended for most cases)
sw-search ./docs --model mini
## Balanced model
sw-search ./docs --model base
## Best quality
sw-search ./docs --model large
## Full model name
sw-search ./docs --model sentence-transformers/all-mpnet-base-v2
```
### File Filtering
```bash
## Specific file types
sw-search ./docs --file-types md,txt,rst,py
## Exclude patterns
sw-search ./docs --exclude "**/test/**,**/__pycache__/**,**/.git/**"
## Language filtering
sw-search ./docs --languages en,es,fr
```
### Tags and Metadata
Add tags during build for filtered searching:
```bash
## Add tags to all chunks
sw-search ./docs --tags documentation,api,v2
## Filter by tags when searching
sw-search search index.swsearch "query" --tags documentation
```
### Searching Indexes
#### Basic Search
```bash
## Search with query
sw-search search knowledge.swsearch "how to create an agent"
## Limit results
sw-search search knowledge.swsearch "API reference" --count 3
## Verbose output with scores
sw-search search knowledge.swsearch "configuration" --verbose
```
#### Search Options
| Option | Default | Description |
| ---------------------- | ------- | -------------------------------- |
| `--count` | 5 | Number of results |
| `--distance-threshold` | 0.0 | Minimum similarity score |
| `--tags` | (none) | Filter by tags |
| `--query-nlp-backend` | nltk | NLP backend: nltk or spacy |
| `--keyword-weight` | (auto) | Manual keyword weight (0.0-1.0) |
| `--model` | (index) | Override embedding model |
| `--json` | false | Output as JSON |
| `--no-content` | false | Hide content, show metadata only |
| `--verbose` | false | Detailed output |
#### Output Formats
```bash
## Human-readable (default)
sw-search search knowledge.swsearch "query"
## JSON output
sw-search search knowledge.swsearch "query" --json
## Metadata only
sw-search search knowledge.swsearch "query" --no-content
## Full verbose output
sw-search search knowledge.swsearch "query" --verbose
```
#### Filter by Tags
```bash
## Single tag
sw-search search knowledge.swsearch "functions" --tags documentation
## Multiple tags
sw-search search knowledge.swsearch "API" --tags api,reference
```
### Interactive Search Shell
Load index once and search multiple times:
```bash
sw-search search knowledge.swsearch --shell
```
Shell commands:
| Command | Description |
| ----------------- | --------------------- |
| `help` | Show help |
| `exit`/`quit`/`q` | Exit shell |
| `count=N` | Set result count |
| `tags=tag1,tag2` | Set tag filter |
| `verbose` | Toggle verbose output |
| `` | Search for query |
Example session:
```
$ sw-search search knowledge.swsearch --shell
Search Shell - Index: knowledge.swsearch
Backend: sqlite
Index contains 1523 chunks from 47 files
Model: sentence-transformers/all-MiniLM-L6-v2
Type 'exit' or 'quit' to leave, 'help' for options
------------------------------------------------------------
search> how to create an agent
Found 5 result(s) for 'how to create an agent' (0.034s):
...
search> count=3
Result count set to: 3
search> SWAIG functions
Found 3 result(s) for 'SWAIG functions' (0.028s):
...
search> exit
Goodbye!
```
### PostgreSQL/pgvector Backend
The search system supports multiple storage backends. Choose based on your deployment needs:
#### Backend Comparison
| Feature | SQLite | pgvector |
| ---------------------------- | ---------------- | --------------------- |
| Setup complexity | None | Requires PostgreSQL |
| Scalability | Limited | Excellent |
| Concurrent access | Poor | Excellent |
| Update capability | Rebuild required | Real-time |
| Performance (small datasets) | Excellent | Good |
| Performance (large datasets) | Poor | Excellent |
| Deployment | File copy | Database connection |
| Multi-agent support | Separate copies | Shared knowledge base |
**SQLite Backend (Default):**
* File-based `.swsearch` indexes
* Portable single-file format
* No external dependencies
* Best for: Single-agent deployments, development, small to medium datasets
**pgvector Backend:**
* Server-based PostgreSQL storage
* Efficient similarity search with IVFFlat/HNSW indexes
* Multiple agents can share the same knowledge base
* Real-time updates without rebuilding
* Best for: Production deployments, multi-agent systems, large datasets
#### Building with pgvector
```bash
## Build to pgvector
sw-search ./docs \
--backend pgvector \
--connection-string "postgresql://user:pass@localhost:5432/knowledge" \
--output docs_collection
## With markdown strategy
sw-search ./docs \
--backend pgvector \
--connection-string "postgresql://user:pass@localhost:5432/knowledge" \
--output docs_collection \
--chunking-strategy markdown
## Overwrite existing collection
sw-search ./docs \
--backend pgvector \
--connection-string "postgresql://user:pass@localhost:5432/knowledge" \
--output docs_collection \
--overwrite
```
#### Search pgvector Collection
```bash
sw-search search docs_collection "how to create an agent" \
--backend pgvector \
--connection-string "postgresql://user:pass@localhost/knowledge"
```
### Migration
Migrate indexes between backends:
```bash
## Get index information
sw-search migrate --info ./docs.swsearch
## Migrate SQLite to pgvector
sw-search migrate ./docs.swsearch --to-pgvector \
--connection-string "postgresql://user:pass@localhost/db" \
--collection-name docs_collection
## Migrate with overwrite
sw-search migrate ./docs.swsearch --to-pgvector \
--connection-string "postgresql://user:pass@localhost/db" \
--collection-name docs_collection \
--overwrite
```
#### Migration Options
| Option | Description |
| --------------------- | ------------------------------------ |
| `--info` | Show index information |
| `--to-pgvector` | Migrate SQLite to pgvector |
| `--to-sqlite` | Migrate pgvector to SQLite (planned) |
| `--connection-string` | PostgreSQL connection string |
| `--collection-name` | Target collection name |
| `--overwrite` | Overwrite existing collection |
| `--batch-size` | Chunks per batch (default: 100) |
### Local vs Remote Modes
The search skill supports both local and remote operation modes.
#### Local Mode (Default)
Searches are performed directly in the agent process using the embedded search engine.
**Pros:**
* Faster (no network latency)
* Works offline
* Simple deployment
* Lower operational complexity
**Cons:**
* Higher memory usage per agent
* Index files must be distributed with each agent
* Updates require redeploying agents
**Configuration in Agent:**
```python
self.add_skill("native_vector_search", {
"tool_name": "search_docs",
"index_file": "docs.swsearch", # Local file
"nlp_backend": "nltk"
})
```
#### Remote Mode
Searches are performed via HTTP API to a centralized search server.
**Pros:**
* Lower memory usage per agent
* Centralized index management
* Easy updates without redeploying agents
* Better scalability for multiple agents
* Shared resources
**Cons:**
* Network dependency
* Additional infrastructure complexity
* Potential latency
**Configuration in Agent:**
```python
self.add_skill("native_vector_search", {
"tool_name": "search_docs",
"remote_url": "http://localhost:8001", # Search server
"index_name": "docs",
"nlp_backend": "nltk"
})
```
#### Automatic Mode Detection
The skill automatically detects which mode to use:
* If `remote_url` is provided → Remote mode
* If `index_file` is provided → Local mode
* Remote mode takes priority if both are specified
#### Running a Remote Search Server
1. **Start the search server:**
```bash
python examples/search_server_standalone.py
```
2. **The server provides HTTP API:**
* `POST /search` - Search the indexes
* `GET /health` - Health check and available indexes
* `POST /reload_index` - Add or reload an index
3. **Test the API:**
```bash
curl -X POST "http://localhost:8001/search" \
-H "Content-Type: application/json" \
-d '{"query": "how to create an agent", "index_name": "docs", "count": 3}'
```
### Remote Search CLI
Search via remote API endpoint from the command line:
```bash
## Basic remote search
sw-search remote http://localhost:8001 "how to create an agent" \
--index-name docs
## With options
sw-search remote localhost:8001 "API reference" \
--index-name docs \
--count 3 \
--verbose
## JSON output
sw-search remote localhost:8001 "query" \
--index-name docs \
--json
```
#### Remote Options
| Option | Default | Description |
| ---------------------- | ---------- | --------------------------- |
| `--index-name` | (required) | Name of the index to search |
| `--count` | 5 | Number of results |
| `--distance-threshold` | 0.0 | Minimum similarity score |
| `--tags` | (none) | Filter by tags |
| `--timeout` | 30 | Request timeout in seconds |
| `--json` | false | Output as JSON |
| `--no-content` | false | Hide content |
| `--verbose` | false | Detailed output |
### Validation
Verify index integrity:
```bash
## Validate index
sw-search validate ./docs.swsearch
## Verbose validation
sw-search validate ./docs.swsearch --verbose
```
Output:
```
✓ Index is valid: ./docs.swsearch
Chunks: 1523
Files: 47
Configuration:
embedding_model: sentence-transformers/all-MiniLM-L6-v2
embedding_dimensions: 384
chunking_strategy: markdown
created_at: 2025-01-15T10:30:00
```
### JSON Export
Export chunks for review or external processing:
```bash
## Export to single JSON file
sw-search ./docs \
--output-format json \
--output all_chunks.json
## Export to directory (one file per source)
sw-search ./docs \
--output-format json \
--output-dir ./chunks/
## Build index from exported JSON
sw-search ./chunks/ \
--chunking-strategy json \
--file-types json \
--output final.swsearch
```
### NLP Backend Selection
Choose NLP backend for processing:
| Backend | Speed | Quality | Install Size |
| ------- | ------ | ------- | ----------------------------------------------------- |
| nltk | Fast | Good | Included |
| spacy | Slower | Better | Requires: `pip install signalwire-agents[search-nlp]` |
```bash
## Index with NLTK (default)
sw-search ./docs --index-nlp-backend nltk
## Index with spaCy (better quality)
sw-search ./docs --index-nlp-backend spacy
## Query with NLTK
sw-search search index.swsearch "query" --query-nlp-backend nltk
## Query with spaCy
sw-search search index.swsearch "query" --query-nlp-backend spacy
```
### Complete Configuration Example
```bash
sw-search ./docs ./examples README.md \
--output ./knowledge.swsearch \
--chunking-strategy sentence \
--max-sentences-per-chunk 8 \
--file-types md,txt,rst,py \
--exclude "**/test/**,**/__pycache__/**" \
--languages en,es,fr \
--model sentence-transformers/all-mpnet-base-v2 \
--tags documentation,api \
--index-nlp-backend nltk \
--validate \
--verbose
```
### Using with Skills
After building an index, use it with the native\_vector\_search skill:
```python
from signalwire_agents import AgentBase
agent = AgentBase(name="search-agent")
## Add search skill with built index
agent.add_skill("native_vector_search", {
"index_path": "./knowledge.swsearch",
"tool_name": "search_docs",
"tool_description": "Search the documentation"
})
```
### Output Formats
| Format | Extension | Description |
| -------- | ---------- | ------------------------------------- |
| swsearch | .swsearch | SQLite-based portable index (default) |
| json | .json | JSON export of chunks |
| pgvector | (database) | PostgreSQL with pgvector extension |
### Installation Requirements
The search system uses optional dependencies to keep the base SDK lightweight. Choose the installation option that fits your needs:
#### Basic Search (\~500MB)
```bash
pip install "signalwire-agents[search]"
```
**Includes:**
* Core search functionality
* Sentence transformers for embeddings
* SQLite FTS5 for keyword search
* Basic document processing (text, markdown)
#### Full Document Processing (\~600MB)
```bash
pip install "signalwire-agents[search-full]"
```
**Adds:**
* PDF processing (PyPDF2)
* DOCX processing (python-docx)
* HTML processing (BeautifulSoup4)
* Additional file format support
#### Advanced NLP Features (\~700MB)
```bash
pip install "signalwire-agents[search-nlp]"
```
**Adds:**
* spaCy for advanced text processing
* NLTK for linguistic analysis
* Enhanced query preprocessing
* Language detection
**Additional Setup Required:**
```bash
python -m spacy download en_core_web_sm
```
**Performance Note:** Advanced NLP features provide significantly better query understanding, synonym expansion, and search relevance, but are 2-3x slower than basic search. Only recommended if you have sufficient CPU power and can tolerate longer response times.
#### All Search Features (\~700MB)
```bash
pip install "signalwire-agents[search-all]"
```
**Includes everything above.**
**Additional Setup Required:**
```bash
python -m spacy download en_core_web_sm
```
#### Query-Only Mode (\~400MB)
```bash
pip install "signalwire-agents[search-queryonly]"
```
For agents that only need to query pre-built indexes without building new ones.
#### PostgreSQL Vector Support
```bash
pip install "signalwire-agents[pgvector]"
```
Adds PostgreSQL with pgvector extension support for production deployments.
#### NLP Backend Selection
You can choose which NLP backend to use for query processing:
| Backend | Speed | Quality | Notes |
| ------- | -------------------- | ------- | ----------------------------------------- |
| nltk | Fast (\~50-100ms) | Good | Default, good for most use cases |
| spacy | Slower (\~150-300ms) | Better | Better POS tagging and entity recognition |
Configure via `--index-nlp-backend` (build) or `--query-nlp-backend` (search) flags.
### API Reference
For programmatic access to the search system, use the Python API directly.
#### SearchEngine Class
```python
from signalwire_agents.search import SearchEngine
## Load an index
engine = SearchEngine("docs.swsearch")
## Perform search
results = engine.search(
query_vector=[...], # Optional: pre-computed query vector
enhanced_text="search query", # Enhanced query text
count=5, # Number of results
similarity_threshold=0.0, # Minimum similarity score
tags=["documentation"] # Filter by tags
)
## Get index statistics
stats = engine.get_stats()
print(f"Total chunks: {stats['total_chunks']}")
print(f"Total files: {stats['total_files']}")
```
#### IndexBuilder Class
```python
from signalwire_agents.search import IndexBuilder
## Create index builder
builder = IndexBuilder(
model_name="sentence-transformers/all-mpnet-base-v2",
chunk_size=500,
chunk_overlap=50,
verbose=True
)
## Build index
builder.build_index(
source_dir="./docs",
output_file="docs.swsearch",
file_types=["md", "txt"],
exclude_patterns=["**/test/**"],
tags=["documentation"]
)
```
### Troubleshooting
| Issue | Solution |
| --------------------------- | -------------------------------------------- |
| Search not available | `pip install signalwire-agents[search]` |
| pgvector errors | `pip install signalwire-agents[pgvector]` |
| PDF processing fails | `pip install signalwire-agents[search-full]` |
| spaCy not found | `pip install signalwire-agents[search-nlp]` |
| No results found | Try different chunking strategy |
| Poor search quality | Use `--model base` or larger chunks |
| Index too large | Use `--model mini`, reduce file types |
| Connection refused (remote) | Check search server is running |
### Related Documentation
* [native\_vector\_search Skill](/docs/agents-sdk/python/guides/builtin-skills#native_vector_search) - Using search indexes in agents
* [Skills Overview](/docs/agents-sdk/python/guides/understanding-skills) - Adding skills to agents
* [DataSphere Integration](/docs/agents-sdk/python/guides/builtin-skills#datasphere) - Cloud-based search alternative