At production scale, voice and AI systems stop behaving like a single sequence of events and start behaving like concurrent systems. This article explains the Double Update failure mode, when two valid asynchronous handlers mutate the same call state at the same time and one update silently overwrites the other, and how to prevent it.
Orchestration Horror Stories: The Double Update
Why Double Updates Break Voice and AI Systems Under Concurrency
At small scale, voice and AI systems feel sequential. One event happens, then another, then another. At production scale, events start to overlap.
Suddenly, two updates arrive at the same time. Both are valid. And one of them quietly erases the other… Context disappears. Decisions stop making sense. The system keeps running, but the conversation doesn’t.
This is the predictable result of architectures that allow multiple asynchronous handlers to mutate shared call state at once.
This problem is known as the Double Update, a failure mode that only appears under real concurrency.
This series breaks down real failure modes that emerge when voice and AI systems scale and how to prevent them. Welcome to part 2: When two correct events arrive… and your system forgets everything
If Zombie Calls are undead, The Double Update is something worse. Nothing gets stuck, nothing crashes, and nothing even looks wrong. At first.
Your system keeps running. Calls keep flowing. Metrics look normal. But somewhere along the way, context disappears.
Act I: A perfectly reasonable assumption
Most voice and AI systems are built on an assumption so common it rarely gets questioned:
“Events arrive one at a time.”
A webhook comes in. You load state from the database. You update it. You save it back. Then the next event arrives.
At low volume, this feels completely safe. Even under moderate load, timing makes it appear safe.
Until it isn’t.
Act II: Two events walk into your app
Here’s the horror scenario:
Event A arrives: “User said something”
Event B arrives: “Transfer initiated”
Both reference the same call
Both arrive at nearly the same time
Each handler does what it was designed to do:
Load current call context
Apply its update
Write state back
But they’re racing.
Event A reads state version N
Event B reads state version N
Event A writes N + A
Event B writes N + B
Whichever one writes last wins.
And the other update? Gone. No error, warning, or retry. Just… missing reality.
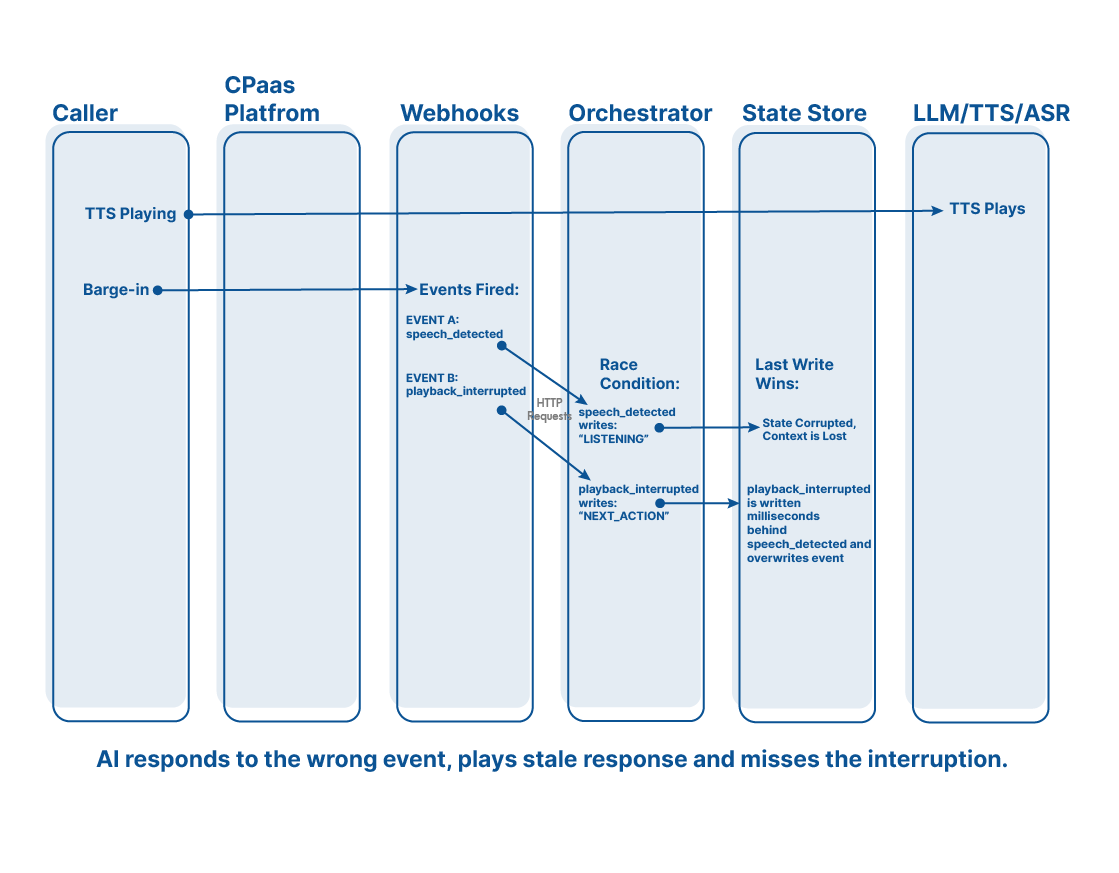
Act III: Context collapse in production
This is where things get expensive.
Suddenly:
The AI voice agent forgets what the caller just said
Transfers happen without explanation
The system repeats questions it already asked
Engineers start adding every safeguard they can think of: Database locks, version checks, retry logic, distributed mutexes.
Each fix slows the system down, adding complexity and creating new failure modes. And still, under enough concurrency, it happens again.
As it turns out, the problem isn’t the database. It’s the model.
Why the Double Update happens
The Double Update is a classic distributed systems failure caused by shared mutable state.
When multiple asynchronous handlers operate on the same external state without a single execution context, it becomes a race instead of a workflow. Even if every handler is “correct,” the composition is not.
Why voice + AI makes this worse
Voice AI systems can amplify this problem dramatically.
In a single moment, you might have:
Speech recognition results
LLM responses
User interruptions
Call control events
Timeout triggers
All firing independently, updating the same call record, and believing they’re the source of truth. This is how systems lose conversational memory: because the architecture erased it.
Orchestration vs. state patching
There are two ways to build these systems:
Option one: Patch state after the fact
Webhooks trigger handlers
Handlers mutate shared state
Concurrency is “managed” with locks and retries
This is where Double Updates live.
Option two: Execute the call as a single flow
Events are handled inside the call context
State is local, not shared
Only one execution path exists at a time
This is orchestration, and it’s why platforms like SignalWire don’t treat calls as records to be updated, but as running programs.
When state lives inside the call’s execution. There is no race to overwrite it, no “last write wins,” and no second update competing for control. Two events don’t collide because they aren’t processed in parallel against shared memory. They’re sequenced by design.
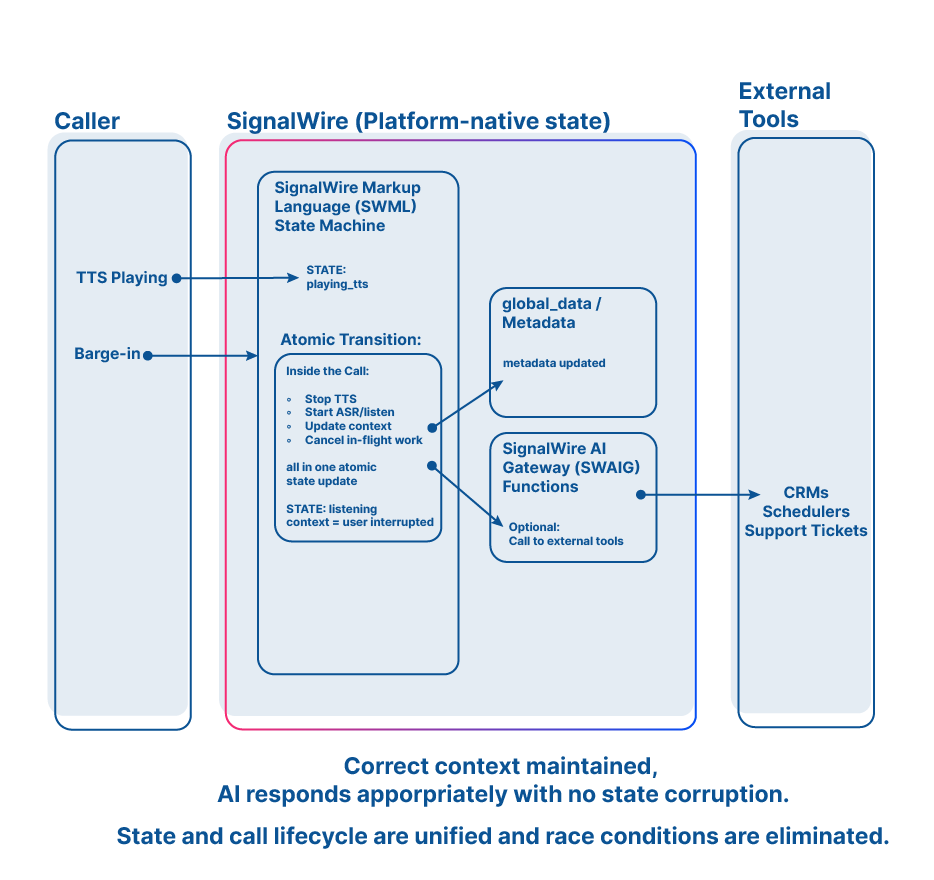
The real lesson of the Double Update
The scariest bugs sometimes aren’t the ones that loudly crash your system, but the ones that silently discard reality.
If your architecture relies on concurrent webhooks, shared call state, or external reconciliation, then losing context becomes inevitable instead of being an edge case.
In the next part of this series, we’ll look at The Phantom Transfer: when a call that no longer exists still manages to reach a human anyway.
Read the rest of the series:
Part 2: The Double Update
Part 4: The Stale Response
Part 5: The Agent Disappears
While you wait for the next installments in this horror series, join our community of developers on Discord to share your stories with our community of voice AI developers.
Ready to build reliable, stateful voice and AI systems? Start building with SignalWire today.
Frequently asked questions
What is the Double Update failure mode?
The Double Update is a concurrency bug where two valid events for the same call are handled in parallel, both read the same state, and the last write overwrites the first. The system keeps running, but part of the call context disappears.
Why does the Double Update happen in voice and AI systems?
Voice and AI stacks generate multiple asynchronous updates, speech recognition results, LLM responses, call control events, timeouts, interruptions, and webhooks. When each handler mutates shared external state independently, the workflow becomes a race instead of a single execution.
What are common symptoms of Double Updates in production?
You see missing context without obvious errors, agents repeat questions, transfers occur without the right intent, the system “forgets” what the caller just said, and debugging points to normal logs and healthy metrics.
Why don’t database locks and retries fully solve it?
Locks, version checks, and retries reduce the frequency, but they add latency, complexity, and new failure modes. Under enough concurrency, you still end up reconciling competing updates because the architecture allows parallel mutation of shared call state.
How does orchestration prevent Double Updates?
Orchestration executes the call as a single running flow. State lives inside the call context, events are sequenced by design, and only one execution path can mutate state at a time, so there is no “last write wins” overwrite.


